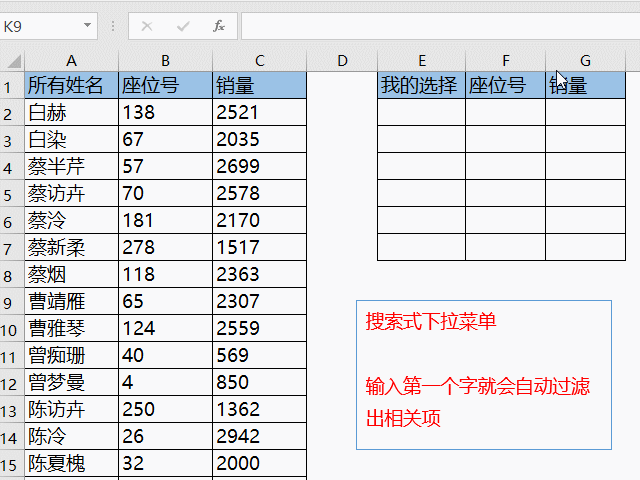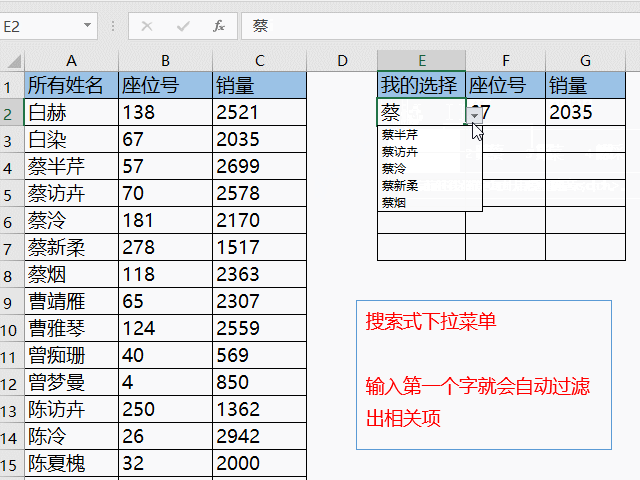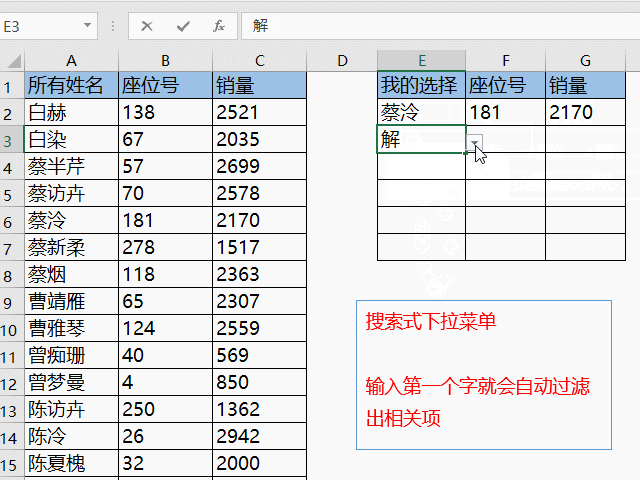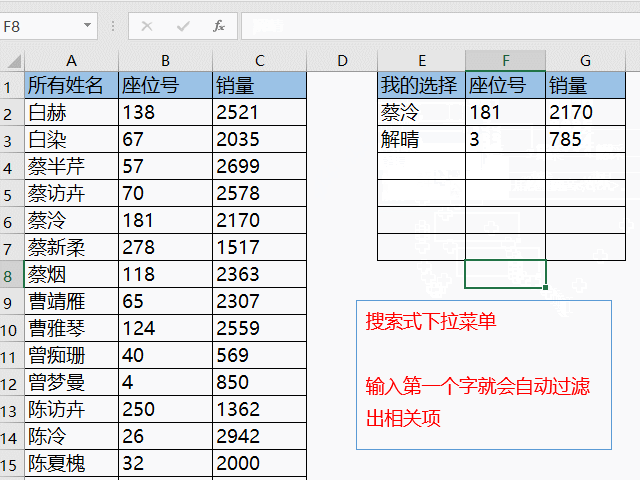
随着互联网的飞速发展,数据量的增长呈现出爆发式的增长趋势。为了更好地管理和分析这些庞大的数据集,大数据软件应运而生。本文将介绍一些常见的大数据软件,以及它们的特点和应用。
Hadoop
Hadoop是一个开源的分布式计算系统,可以用于处理大规模数据集。它可以自动将数据分布在多台计算机上,并对数据进行分析和处理。Hadoop的核心组件包括HDFS和MapReduce。HDFS是一个分布式文件系统,可以存储大规模数据集。MapReduce是一种编程模型,可以对数据进行并行处理。
Hadoop的优点在于它可以扩展到数千台计算机,可以处理PB级别的数据。此外,Hadoop还有非常活跃的开发社区,可以提供免费的技术支持和培训资料。
Spark
Spark是一个快速的通用计算引擎,可以用于大规模数据处理。它可以在内存中执行计算任务,比Hadoop更快。Spark不仅支持MapReduce编程模型,还支持SQL查询,流处理和机器学习等应用。
Spark的优点在于它可以处理实时数据流和批处理数据,以及支持多种语言,包括Java,Python和Scala。此外,Spark还提供了许多内置的算法和工具,可以帮助用户快速构建大规模数据处理应用程序。
Cassandra
Cassandra是一个开源的分布式NoSQL数据库系统,可以用于存储大规模数据集。它可以处理PB级别的数据,并提供了高可用性和可伸缩性。
Cassandra的优点在于它具有高性能和可扩展性,可以在多台计算机上运行。此外,Cassandra还支持数据复制和数据备份,可以确保数据安全。
Elasticsearch
Elasticsearch是一个开源的搜索引擎,可以用于处理大规模数据集。它可以快速地搜索和分析数据,并提供了非常高的数据可视化效果。
Elasticsearch的优点在于它可以快速搜索和分析大规模数据集,以及支持多种查询和筛选方式。此外,Elasticsearch还提供了许多内置的数据分析工具和可视化效果,可以帮助用户更好地理解数据。
综上所述,大数据软件的应用范围越来越广泛,它们不仅可以用于处理大规模数据集,还可以用于实时数据处理和数据分析。各种大数据软件都有其独特的特点和优点,用户可以根据自己的需求选择最适合的软件。
结论
本文介绍了一些常见的大数据软件,包括Hadoop,Spark,Cassandra和Elasticsearch。这些软件都具有各自独特的特点和优点,可以用于处理大规模数据集。希望读者可以根据自己的需求选择最适合的软件,以便更好地管理和分析数据。
参考资料
《Hadoop权威指南》
《Spark快速大数据分析》
《Cassandra权威指南》
《Elasticsearch权威指南》